


 Visit the Project VGA Page
Visit the Project VGA Page




Anyhow.
Posted on 2006/10/17 - 21:35Right, after the whole server story of yesterday I figured "What the hell" and started setting up my local FreeSCO router to forward some ports to the internal server. That, unfortunately, kept me busy all day, and it's still not working. It doesn't really matter anyhow because the local server needs a good polishing before I can really 'toss it online'. It starts to look like a whole lot more work than I first anticipated. Lets just hope these problems are temporary, otherwise the motivation will drop below acceptable levels before the damn thing is online.
Another this I mentioned yesterday was that I had loads of things to report before I could get back on schedule, and that I was writing other stuff instead of a weblog engine. Well then, let's take a little sneak peek at one of these items, shall we? The subject of today is... perennial.
From the Oxford American Dictionaries;
perennial | adjective,
lasting or existing for a long or apparently infinite time; enduring.
That roughly describes how long I've been working on the theory behind this tool, so I decided to use it as a name. The idea behind perennial comes from my development of an Artificial Intelligence, which was to support plain text input/output. I was crushing away a medical book I borrowed from my (back then) roommate who was studying psychology, when I had this rough idea in my head of how neurons in a 'natural' (don't want to say human here, that makes it sound like animals don't have one) brain store information through data abstraction. And then it struck me; with this method I could (Ahem, here we go) "save a vast amount of low-entropy data in an ordered, database accessible format while simultaneously compressing the overall size compared to the original input". After I cried that out, my roommate cracked up laughing and passed me back the joint we we're smoking.
The next day however, I figured I'd take a second (more sober) look at the idea. True, the law that the output could in theory never be smaller than the input was still in effect, and after sufficient time the database would be saturated, actually getting bigger than the input. But since the input would be low-entropy (for you non-insiders; it'd be english. Lot's of same word and letter combinations) that saturation point would be far, far away. I might be actually on to something! From there it turned into a more solid theory, into another theory, into yet another one, until finally it became somewhat of an 'holy grail' (again for the non-insiders; obsession) for me.
At some point I figured I'd build this part of the theory first, and the AI later. Then I went on doing some other stuff, occasionally pondering about Life, the Universe, and Everything. And this Damn Thing. Until last week somewhere, where I figured I'd give a sling shot at a rough implementation, just to see how it would perform 'so far'. The algorithm is not exactly how I want it, is terribly slow and un-optimised, and misses most of the 'database' part. Still, it compresses and makes pretty pictures;
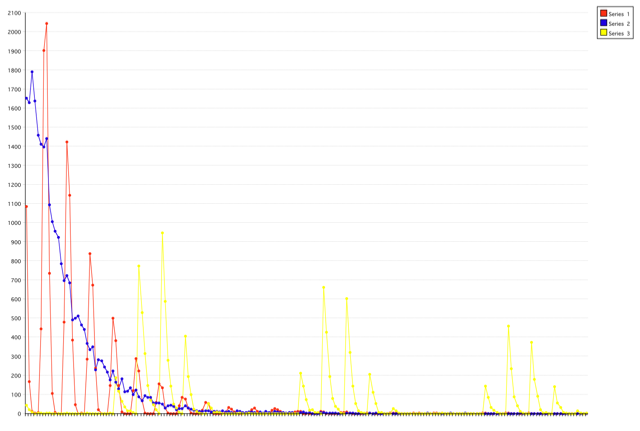
That's Lewis Carroll's "Alice in Wonderland" for you. It makes sense to me, but I'm not even going to try and explain it to you. Oh, and did I say that it actually works? Some hard numbers;
163218 Bytes, alice30.txt (original)
72583 Bytes, alice.hex (perennial)
47765 Bytes, alice.txt.bz2 (bzip2)
Now take a grain of salt with this. It looks like I'm getting a 2.2x compression, but I haven't fully verified the output yet. Also for comparison I listed the tool bzip2 which is pretty much one of the industry standards and scores a 3.4x compression rate. And before you shout "Yours is worse!" remember three things; 1) Mine isn't finished, 2) Bzip2 has been in development for years, by professionals, 3) Name all the people you know who've designed their own compression algorithm from the ground up.
Heck, even in it's current status I could probably apply for a patent if I wanted to. But I don't. This is science, not a commercial product. Can you imagine Pythagoras patenting the Pythagorean theorem just because he can? How silly that may even sound, it's what happened in the past a few times, especially if we'd look in the direction of the LZW algorithm. Oddly enough, the LZW algorithm can be considered as a (very) 'primitive form' of my algorithm, but I only found out about that recently. And I'm actually slightly worried that LZW would do a better job at Alice in Wonderland than my algorithm, so to get back to my point; it's not time for patents and other legal stuff just yet.
Enough history, vague results and silly daydreaming, I'm going to end this 'weblog' entry. I'll keep you updated about any progress on this tool! G'night!
[: wacco :]